

大家好,我是安晓颜,昨天刷推,无意间看到a16z最新的AI榜单,我的目光一下子被吸引住了 —— 全球Top 50 AI web/app应用中,竟然有两款来自同一家中国公司的产品双双上榜!海螺AI(web排行榜)和Talkie(app排行榜),这在中国AI公司里算是凤毛麟角的存在了。其中海螺Al(Hailuo Al)更是力压可灵和Sora,在AI视频生成领域登顶全球第一

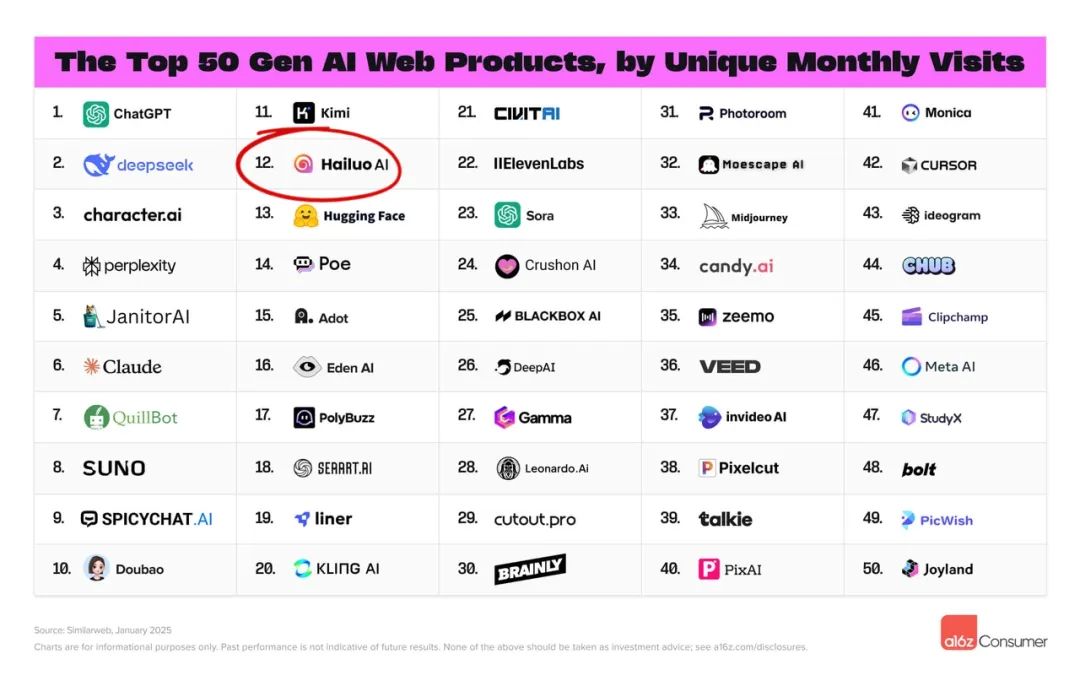
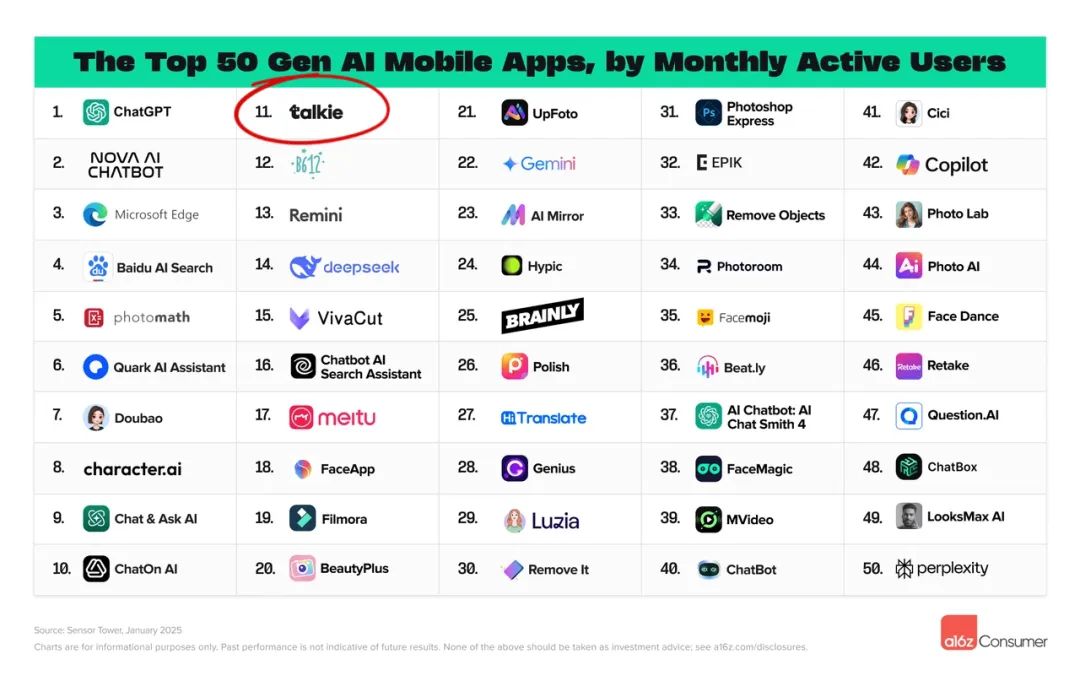

PS:a16z(Andreessen Horowitz)是硅谷最具影响力的风险投资机构之一,是投中 OpenAI、Anthropic、Character.AI的顶流风投,自家还囤了 2 万台 H100 显卡(比某些小国的算力都多)。其AI榜单在科技和投资圈具有相当高的含金量,甚至有人将其榜单称为 AI 界 “照妖镜”:因为能上 a16z 的榜,相当于被硅谷最懂 AI 的 “星探” 相中啦 —— 用户是真的在用产品,不是靠 PPT 吹牛!毕竟上榜的基础条件是月活至少达到800万~
而这家公司就是来自中国上海的稀宇极智(MiniMax)

中国AI的国际舞台新势力

说起MiniMax,这家成立于2021年的AI科技公司还真不简单。由人工智能头部上市公司--商汤集团前副总裁 闫俊杰创立,公司汇聚了一批顶尖AI人才,包括前上海人工智能实验室青年科学家钟怡然等技术大牛。短短几年,MiniMax就在大模型领域实现了从0到1的突破,并成功打造了海螺AI和Talkie等爆款AI产品。
模型的迭代创新,是MiniMax的C端产品拥有更好体验的立足之本:在开年后,MiniMax发布了一系列模型,其中包括最新的视频模型S2V-01,基于其“主体参考”功能,让用户只需输入一张图片, 即可实现视觉细节的精确还原;目前在海螺AI视频就能用。
在今年1月,MiniMax还开源了他们的旗舰模型MiniMax-01(比DeepSeek R1还早4天发布),这个模型跟其他大模型都不太一样,不走传统的Transformer技术架构,而是另辟蹊径,首次在商业级大模型中大规模实现了线性注意力机制,模型参数量高达4560亿,性能直追GPT-4o和Claude-3.5-Sonnet。最关键的是它能够高效处理全球最长400万token(4M)的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍!上下文长度这块对其他开源大模型来说是绝对的降维打击了。
出于好奇,我把他们的开源模型:MiniMax-01和最新视频模型:S2V-01都体验了一下,真的惊艳到我!
超长上下文:400万tokens的怪物
最让我震惊的是MiniMax-01的上下文长度 —— 400万token!这是什么概念?如果按中文1字=1.7 tokens,英文1字=1 tokens来算,大约能一次处理235万字中文,400万字英文!
体验地址帮大家贴出来了
https://chat.minimaxi.com/
为了测试长上下文效果,我本来想把整本斗破苍穹小说丢给MiniMax-01分析的,但是有可能已经被它作为训练的语料学习过了,所以我找了辰东在24年9月份新上线的小说--《夜无疆》,目前还在持续更新中,已有108万字了!
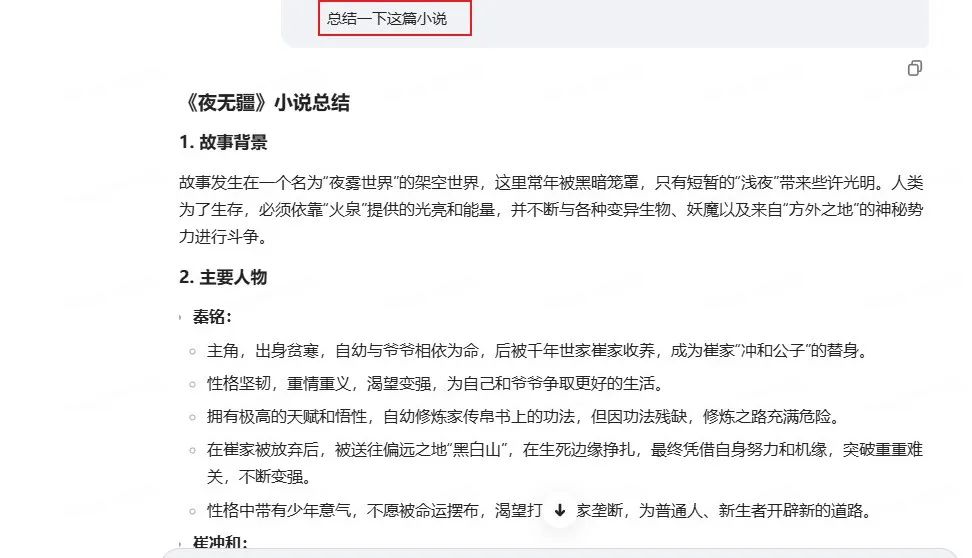
我直接让它总结一下这篇小说
它总结的非常细致,从故事背景,主要人物,故事梗概,小说特色面面俱到。
然后我让它找小说里面的一段小高潮部分,在哪些章节,MiniMax-01完美的给出了准确答案~
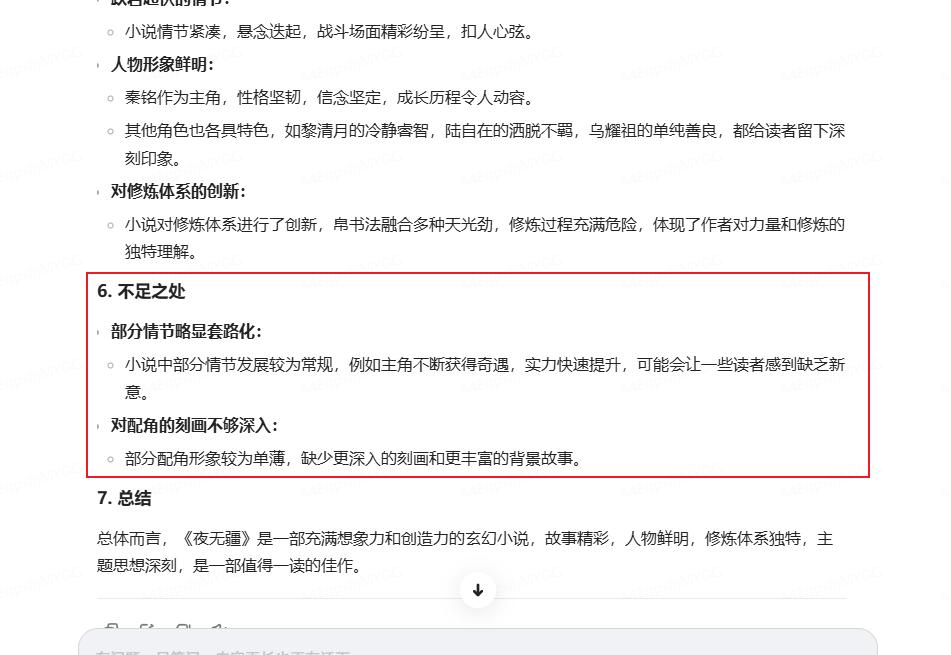

最后,我甚至让它续写小说,由于它能理解整个小说前面所有的上下文,续写起来真有那味儿!续写的内容读起来毫无违和感!文笔、风格完全一致!故事情节也是承上启下,不得不说小说家有福了。

更夸张的是,在处理这么长的文本时,MiniMax-01的性能衰减是所有模型中最慢的,甚至显著优于Google的Gemini。
在400万token的"大海捞针"检索任务中,MiniMax-01全绿!这意味着即使在海量信息中,它也能精准找到关键内容,不会像其他模型一样"记忆力衰退"。

这么说来,要是把这玩意儿集成到RAG中,那知识库问答效果岂不爆炸?说干就干,先在minimax的开放平台创建apikey,并保持备用。
apikey创建地址:
https://platform.minimaxi.com/user-center/basicinformation/interface-key
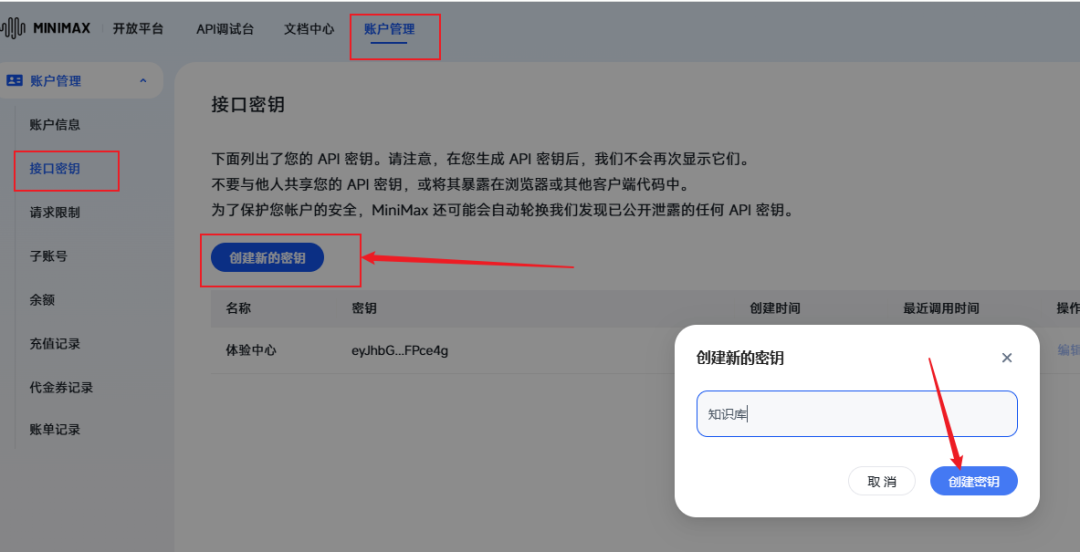
在fastgpt中接入minimax-01(打开账号->模型提供商->模型配置->新增模型->语言模型)
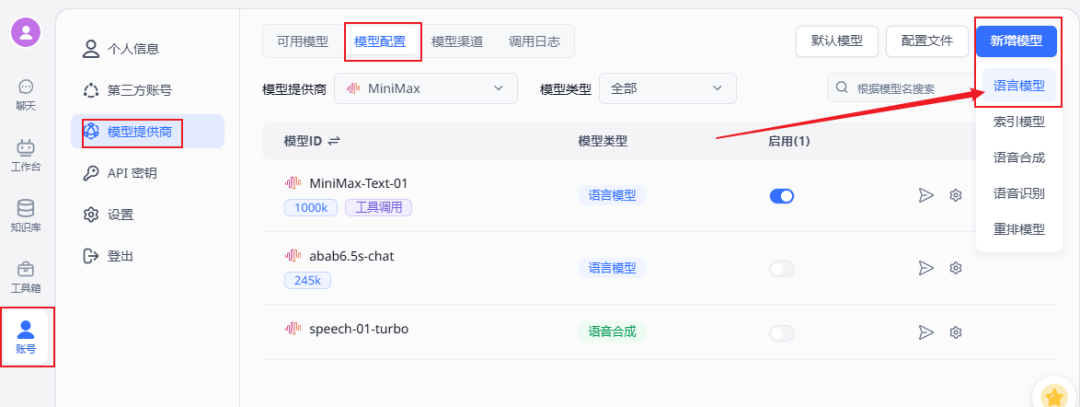
模型提供商选择MiniMax
模型名称填:MiniMax-Text-01(其他配置参考下图)
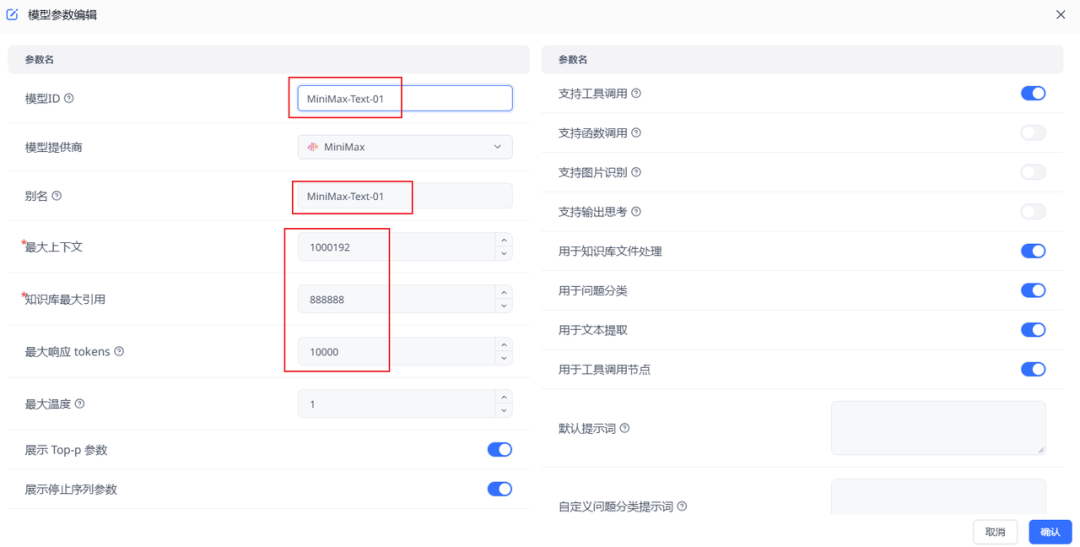
粘贴API请求地址和apikey
API请求地址(兼容OpenAI请求方式):
https://api.minimax.chat/v1/chat/completions
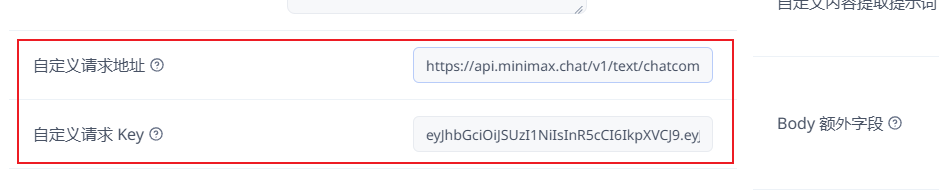
API价格非常感人:每百万输入 Token 1 元/输出 Token 8 元,意味着你 大几百万字 的小说、论文放进去,只需要几块钱!这性价比绝了。

并且还支持function call,web搜索,图片识别,太全能了呀。
为了测试,我调整了一下fastgpt知识库的配置:引用上限拉到最高,最低相关度拉到最低!
这样基本上一次检索,会把知识库内所有相关信息全部提取出来(甚至只是沾边的信息也可以提取出来)
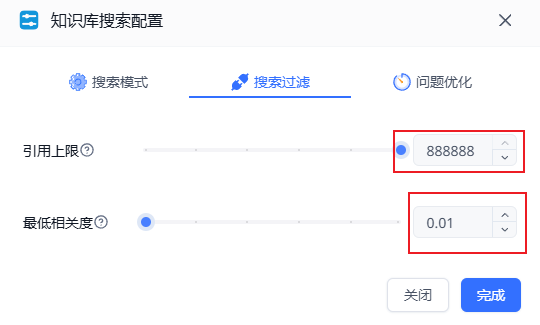
在同等条件下,使用DeepSeek V3的知识库回答效果如下:
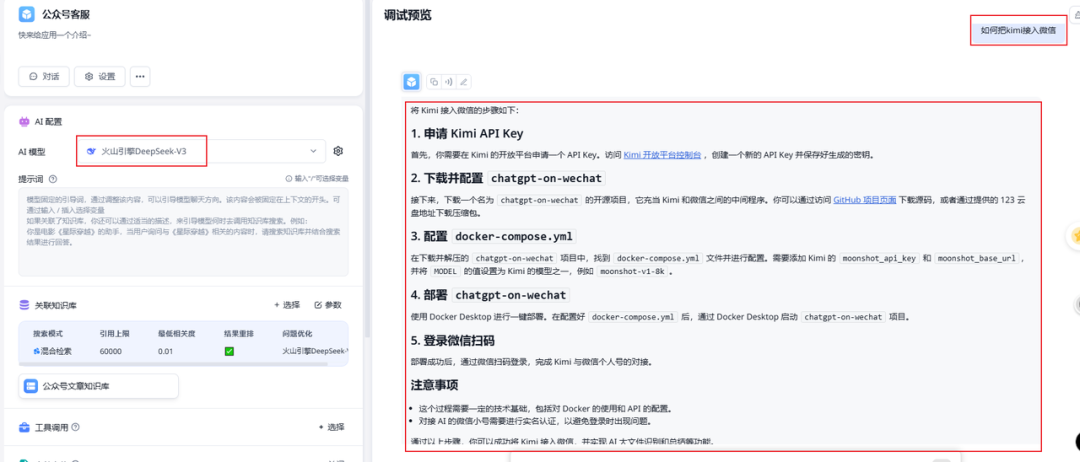
而使用minimax-01的知识库回答效果(如下图)更加详细,而且全面,把知识库中提到的所有方式都回答出来了。
PS:如果你的知识库内容并不算多的话,甚至可以完全不使用RAG了,直接把整个知识库内容放在system prompt中,每次提问都带上~
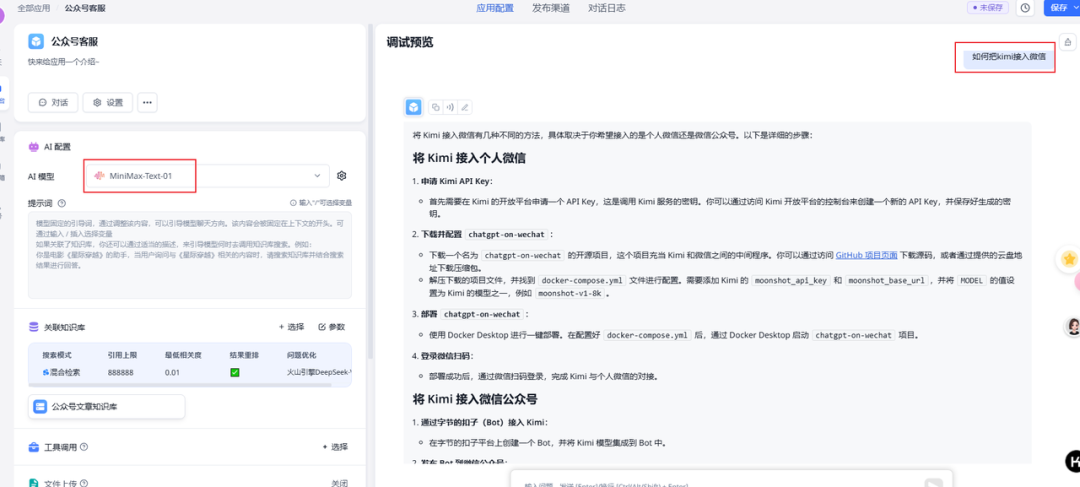
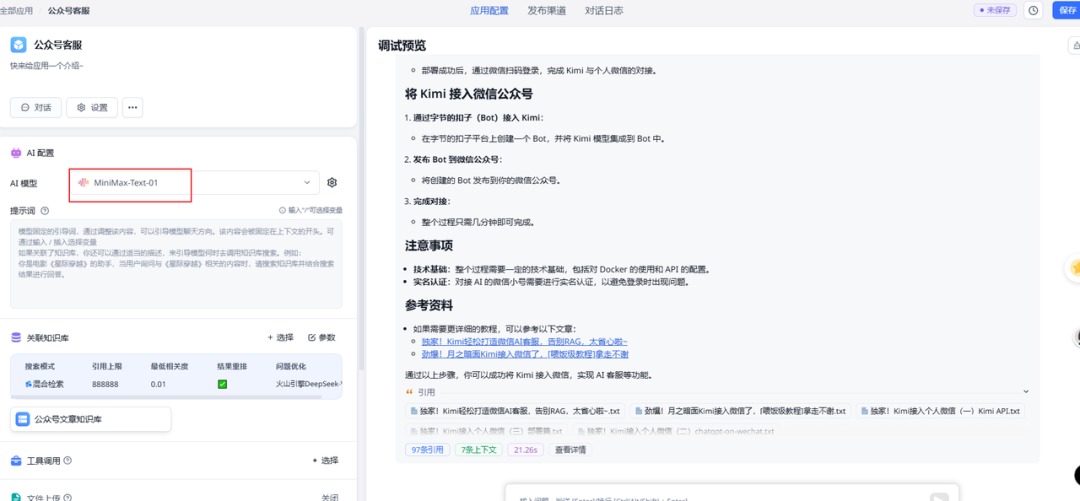
之前我的知识库语言模型用的是DeepSeek V3,因为它足够便宜,性价比高。但是上下文长度是它的硬伤,只有64k的上下文长度。
而minimax-01支持的上下文长度是DeepSeek的62.5倍!还支持function call,和网络搜索功能,价格还更香,所以后续知识库的语言模型我准备换成MiniMax-Text-01了。
海螺AI:AI视频领域的top1
说到MiniMax的产品,又不得不提他们的海螺AI(Hailuo)。这款产品凭借强大的视频生成能力,从去年9月至今都是全球AI视频产品榜榜首。

海螺AI在视频生成领域有什么过人之处?a16z的报告给出了答案:
https://a16z.com/100-gen-ai-apps-4/
简单说,就是海螺AI对提示词的执行力极强,能够精准还原用户的创意意图。这一点对视频创作者来说绝对是"救命稻草" —— 不用反复调整提示词,就能得到想要的效果。
而MiniMax最新自研的视频模型:S2V-01——可以通过单图主体参考架构,仅需用户输入一张图片,能以极低的输入和计算成本,实现视觉细节的精确还原,同时具备高自由度和组合性。
S2V-01模型还能准确识别照片中不同性别、年龄、肤色、五官结构等面部特征,所生成的角色稳定、连贯,且在每一帧中均可以保持角色一致。
2月份他们又更新了导演系列模型T2V-01-Director、I2V-01-Director。用户甚至可以控制镜头,自己当导演~
访问海螺AI视频创作平台--
国内用户创作入口:hailuoai.video/create
海外用户创作入口:hailuoai.com/video/create
用户可在海螺AI中选择“主体参考“功能后进行体验。(截图为国内用户创作入口)
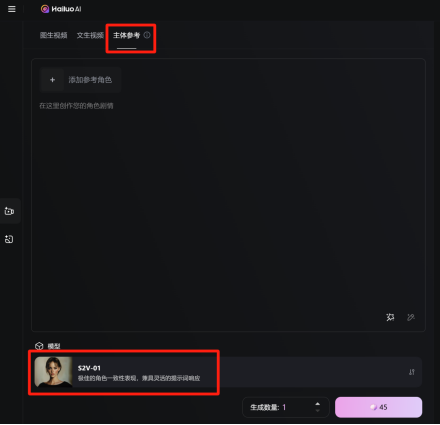
点击“添加参考角色”上传参考图片:选择一张包含你想要生成视频的主体的图片。上传图片建议选择背景干净、人物正脸大头的素材(人物一致性主要参考锁定的是上传图片的面部五官和肤色等特征,服装部分目前需要依靠提示词来完成)。
如果上传图片未检测到人像就无法进行主题参考,需要重新选择素材上传。
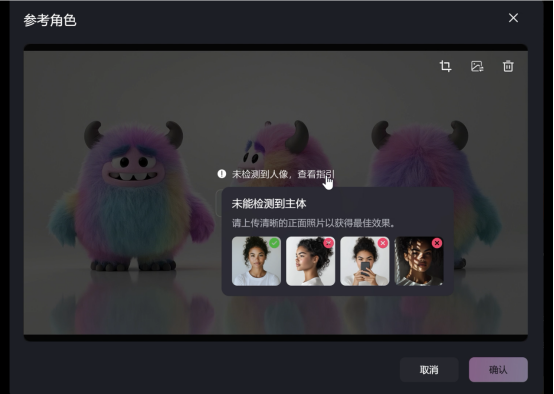
正式体验SV2-01的核心功能前,让我们先来get一个提示词小公式:
SV2-01的提示词=人物外貌+人物动作+人物服装+人物神态/表情+故事发生场景+灯光/质感/运镜
使用该模型,镜头景别不建议使用远景和大全景,中近景效果更好,越贴脸的角度和景别角色一致性就越高,没有特别想要表达的内容也可以不加该部分提示词,随机性较强。
上传一张旗袍女孩的高清图

输入提示词:
穿着白色旗袍的女人走在一座古镇里,她神情优雅从容的慢慢走向镜头,高级质感,电影质感,光线明亮,氛围感灯光。
整体效果较好,一致性不错,但可能因为我上传的是3/4侧脸,所以大家尽量选择正脸上传效果会更佳。
沿用这张人物角色图,我们换个风格,输入提示词:
穿着黑色紧身衣的女人拿着一把冲锋枪,她神情严肃谨慎,她的眼睛逐渐睁的更大,她贴墙站着,背景是一座废弃的工厂,中近景,跟随镜头。高级质感,电影质感,电影光线,冷色调灯光。
对比上个视频,会发现生成视频的色调与上传参考图色调要求一致(比如我的原图是冷色调,这里提示词也要求冷色调)时,角色一致性也会显著提升。高自由度+组合性体现的淋漓尽致,两个视频的角色表现总体都较稳定,跟随镜头也表现良好。
继续沿用这张人物角色图,我们玩点有趣的,输入提示词:
一个穿着华丽梦幻粉色公主裙的女人,她开心的向周围挥手打招呼,她表情轻松愉快,她在一座游乐园里走着,固定镜头,中近景。高级质感,电影质感,氛围感,暖色调,光线明亮。
在你每次输入提示词后,minmax还会帮你进行优化再输出视频,强烈的语义理解和上下文推理能力让我们得到该视频。
不知道的还以为它也在欢乐谷做过互动npc:夜景,乐园,光线,互动真实感都拉满还原。
继续操作,我们上传一张阳光开朗大男孩的图片。

给阳光开朗的他换个小资腔调试试,输入提示词:
一个穿着西装的老爷爷,他坐在办公室里喝着咖啡,表情轻松,固定镜头,中近景。高级质感,电影质感,氛围感,冷色调,光线明亮。
蓬松的秀发,开朗迷人的笑容,整齐又微微发白的胡须,神态和动作都从容优雅,视觉细节的精准还原,是他就是他,一眼就能认出他!
真人没意思,换一题,我们再考考它。
3D动画风格,输入提示词:
一个小男孩,他穿着一个蓝色的短袖,披着红色的披风,表情严肃,他手里举着一把剑,站在一个卧室里,中近景,跟随镜头。高级质感,电影质感,氛围感,暖色调,光线明亮。
完美的还原了人物服装,场景,视频色调和画面质感,降低了用户的输入成本,不知道的还以为是皮克斯上线的新电影hhhh~
再来一题上点难度,换个物种我们蹲蹲看——

给肌肉健壮且聪明绝顶的它输入一段提示词:
一个外星人,他在一个酒吧里穿着大白褂跳舞,表情平静,中近景,固定镜头。高级质感,电影质感,氛围感,冷色调,光线明亮。
SV2-01拥有丰富的知识库和推理能力,可生成流畅、连贯的文本和创意内容。一身班味的你想找点不一样的乐子平静的释放浑身疲惫?直接玩起来啊!
当然啦,除了以上视频外,你还可以开启更多奇思妙想,玩转SV2-01,一些其他的优化使用建议我就附在这里啦。
1. 使用720p、25fps的高清图像获得更好的视觉理解效果
SV2-01模型通过多轮对话持续优化,能够根据反馈调整输出,是一款适用于多个场景的强大AI助手。
线性注意力:3年/3700次实验的技术突破
说完海螺AI的视频能力,我们不得不回到MiniMax最核心的技术突破上来。因为无论是视频生成还是多模态理解,背后都离不开强大的基础模型支撑。而MiniMax-01作为公司的旗舰语言模型,正是整个技术体系的基石。
那么,MiniMax-01的核心秘密武器是什么?答案是线性注意力机制(Lightning Attention)。
传统Transformer的注意力机制计算复杂度是O(n²),这意味着当序列长度翻倍时,计算量会增加4倍。而线性注意力将复杂度降至O(n),序列长度翻倍,计算量只增加2倍。这就是为什么MiniMax-01能处理如此长的上下文还能"面不改色"
技术突破并非一蹴而就。MiniMax团队从2021年就开始研发,当时这还只是一个"看起来很美好的愿望"。为了验证这个技术能否在大规模模型上work,他们进行了惊人的3700次预训练实验!
最终,他们发现纯线性注意力在"大海捞针"任务上存在缺陷,于是创造性地提出了"7混1"结构 —— 每8层中有7层是线性注意力,1层是传统SoftMax注意力。这个混合架构在100万token序列长度下实现了2700倍加速,同时模型效果甚至优于纯Transformer!
这种架构创新不是简单的堆参数,而是从根本上重新思考了大模型的计算方式。MiniMax高级研发总监钟怡然在一次播客中透露,公司投入了超过80%的研发资源在这个项目上,这是一次真正的技术赌注。
现在看来,他们"赌"成功了!
Agent时代的基础设施
最后我想说MiniMax-01的意义远不止于一个强大的模型,它代表了Agent时代的基础设施。
关键在于它好用,便宜,人人都用得起。更关键的是提供超长上下文长度。
想象一下,当AI需要处理复杂任务时,往往需要长时间的"思考链",需要持续记忆大量信息。无论是单Agent系统需要持续记忆,还是多Agent系统中Agent之间的大量相互通信,都需要越来越长的上下文支持。
而MiniMax-01的超长上下文和高效处理能力,恰恰为这种复杂场景提供了便利。它不仅能记住更多信息,还能在海量数据中精准检索,这对构建真正智能的Agent至关重要。
据说MiniMax计划将在4~5月发布基于Linear Attention架构的深度推理多模态模型,到那时,中国AI的国际影响力将进一步提升。这不仅是技术的进步,更是中国AI从跟跑到并跑,甚至在某些领域领跑的重要标志。
在这个AI技术爆发的时代,MiniMax和DeepSeek等中国公司的创新,正在为全球AI发展贡献着独特的中国智慧。
我感觉,现在我们被科技信息刷屏的间隔明显越来越短。多年后回望历史,相信会感叹我们很幸运的处在了AI爆炸的元年,见证了AI技术的指数式发展,从Deepseek、Manus,再到Minimax,来自中国的团队们真的创造了太多奇迹,很难不说一句——Created in China(中国创造),我骄傲!


")

还没有评论,来说两句吧...