

在处理书籍或文档的PDF文件时,尤其是扫描版的PDF,我们常常需要从中提取文本内容。这一过程传统上依赖于OCR(光学字符识别)技术。近年来,随着大语言模型的发展,结合OCR和NLP的智能文档处理方式正成为解决实际问题的强大工具。本文将介绍如何利用本地部署的多模态大语言模型(如Qwen2.5-VL)实现从PDF文件中提取文字内容并完成OCR任务,最终将其转换为Markdown文档。
二、模型选择与本地部署
1. 模型选择
在选择模型时,我们考虑了模型的性能、参数量以及是否能在本地部署。Qwen2.5-VL是一个基于Transformer架构开发的多模态模型,它能够处理图像和文本输入,非常适合我们的任务需求。
2. 本地部署
我们选择了Hugging Face的Transformers库来加载和使用Qwen2.5-VL模型,并使用vLLM来优化模型的推理性能。以下是本地部署的主要步骤:
安装Transformers库和vLLM。
下载Qwen2.5-VL模型文件到本地指定目录。
bashCopy Codepip install transformers vllm# 使用modelscope下载模型(如huggingface-cli不方便使用)pip install modelscope modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir ../local_models/Qwen2.5-VL-3B-Instruct
三、PDF到Markdown的转换流程
1. PDF处理阶段
首先,我们需要将PDF文件转换为图像序列。这一过程可以使用PDF处理库(如PyMuPDF或pdf2image)来实现。
2. 模型初始化
加载指定的视觉语言模型Qwen2.5-VL,并准备好进行OCR任务。
3. 图像处理与转换
对每个PDF页面生成的图像进行处理,使用Qwen2.5-VL模型识别图像中的文本、表格、图片等内容,并将其转换为Markdown格式的文本。
4. 结果整合与输出
合并所有页面转换得到的Markdown内容,并将最终的Markdown文本保存到指定的输出文件中。
四、性能测试与效果展示
我们在两款不同的电脑上进行了测试:Macbook Air M3处理器,16G内存;以及Ubuntu服务器,配备V100 GPU和32G显存。测试结果显示,在V100上处理一页PDF仅需10秒左右,而在Macbook Air上则需要几分钟。这显示了GPU加速对于提高OCR任务效率的重要性。
转换效果方面,从PDF文件中提取的图像能够准确地
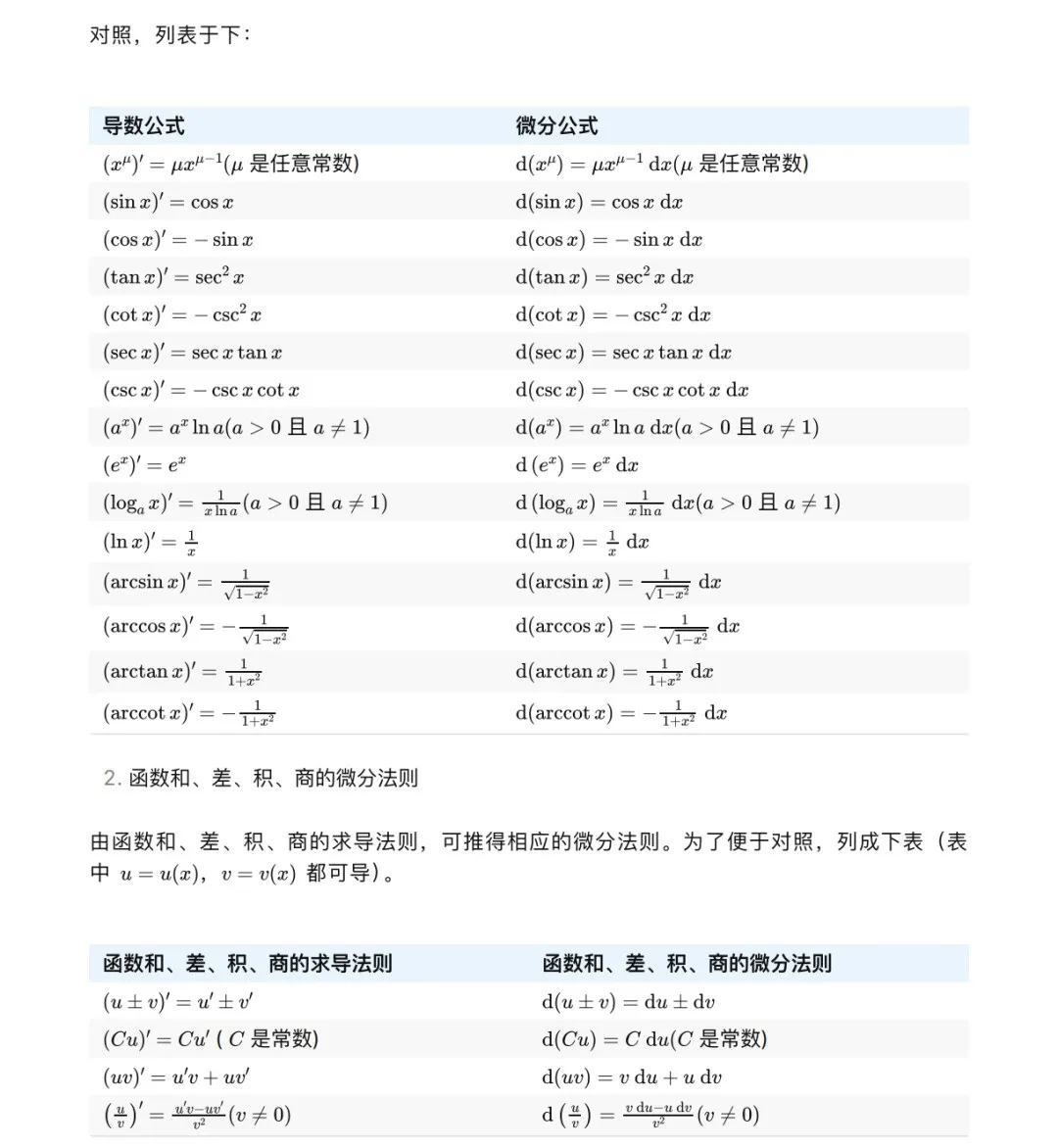
转换为Markdown格式的文本,包括文字、表格和数学公式等。这证明了我们的方法在处理复杂视觉语言任务时的有效性。
本文介绍了如何利用本地部署的多模态大语言模型实现从PDF到Markdown的转换。通过选择合适的模型、进行本地部署以及设计高效的转换流程,我们成功地实现了这一目标。该方法为后续更复杂任务奠定了基础,如自动化文档处理、智能信息提取等。未来,我们将继续探索和优化这一方法,以应对更多样化的应用场景和挑战。



还没有评论,来说两句吧...