

在人工智能领域,视觉大模型的竞争日益激烈。今天,我要为大家介绍一款性能卓越且完全免费的开源视觉大模型——Gemma 3。
模型概述
Gemma 3 是由谷歌推出的顶尖开源多模态大模型之一。它具备多语言支持能力,涵盖超过 35 种语言,能够同时对文本、图像以及短视频进行分析处理。其视觉编码器经过优化升级,不仅能够处理高分辨率图像,还兼容非方形图像。此外,Gemma 3 引入了 ShieldGemma 2 图像安全分类器,可有效识别并过滤掉含有性暗示、危险或暴力元素的内容。
模型优势
1. 高效的多模态处理能力
Gemma 3 能够同时处理文本、图像和短视频等多种数据模态,并在这些模态之间进行有效的交互和信息整合。
2. 优化的视觉编码器
能够处理高分辨率和非方形图像,适应更多样化的输入需求。
3. 图像安全分类器
引入 ShieldGemma 2 图像安全分类器,确保生成内容的安全性和适宜性。
4. 强大的语言支持
提供对超过 35 种语言的开箱即用支持和对超过 140 种语言的预训练支持。
5. 扩展的上下文窗口
Gemma 3 提供 128k 令牌上下文窗口,能够处理和理解大量信息。
6. 函数调用和结构化输出
支持函数调用和结构化输出,帮助用户自动执行任务并构建代理体验。
7. 官方量化版本
引入官方量化版本,减少模型大小和计算要求,同时保持高精度。
模型评分与排名
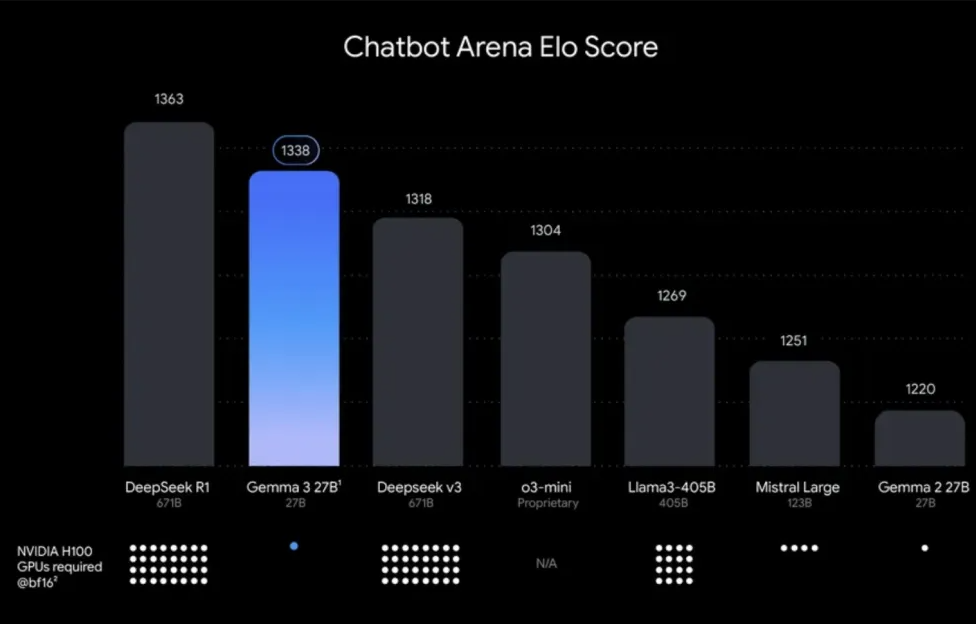
在 LMArena 排行榜的初步人类偏好评估中,Gemma 3 凭借其先进的性能胜过 Llama3-405B、DeepSeek-V3 和 o3-mini 等模型。以下是 Gemma 3 与其他模型的评分和 GPU 需求对比:
| 模型名称 | 参数量 | 评分(分) | GPU 需求(NVIDIA H100 数量) |
|---|---|---|---|
| DeepSeek R1 (67B) | 67B | 1363 | 12 |
| Gemma 3 27B | 27B | 1338 | 1 |
| DeepSeek v3 (67B) | 67B | 1318 | 12 |
| o3-mini (Proprietary) | - | 1304 | N/A |
| Llama3-405B (405B) | 405B | 1269 | 6 |
| Mistral Large (123B) | 123B | 1251 | 4 |
| Gemma 2 27B | 27B | 1220 | 1 |
本地部署 Gemma 3
1. 安装 Ollama
本地安装 Gemma 3 时,建议使用 Ollama 工具。普通用户可以选择 4b 或 12b 版本,显卡性能较好的用户可以选择 27b 版本。以下是安装命令:
ollama run gemma3:1b
ollama run gemma3:4b
ollama run gemma3:12b
ollama run gemma3:27b2. 使用 Chrome 插件调用本地 Gemma 3
可以通过以下链接下载 Chrome 插件,实现与本地 Gemma 3 模型的交互:

获取更多精彩内容请付费查看或下载, 谢谢支持!
3. 图片识别
提供一张生物眼球参数图片,让 Gemma 3 进行识别和分析:

4. 图片编辑
提供一张图片,让 Gemma 3 进行编辑。例如,将吊带改为红色并给女主角带上墨镜:


编辑后的效果如下:

Gemma 3 作为一款强大的开源视觉大模型,具备多模态处理、高分辨率图像支持、多语言处理等多种优势。通过本地部署,用户可以在自己的设备上免费使用这一模型,满足各种视觉和文本处理需求。希望这篇教程能够帮助你成功部署并体验 Gemma 3 的强大功能。




还没有评论,来说两句吧...